























































 更新时间:2026-06-17 08:36:51
更新时间:2026-06-17 08:36:51 开发经验
开发经验 1150
1150最近看到高端SEO社群里有同学讨论Robots相关问题,我们从实战的角度,给大家讲讲怎么写Robots写法,以及在实战中可能遇到的问题,都给大家讲一下!希望可以帮助更多不懂的同学!
Robots定义
什么是Robots,简单来讲,其实Robots就是放在网站根目录下的一个TXT文件,但是这个TXT文件对搜索引擎规定,哪些页面可以访问,哪些页面不行。
Robots一般放在网站根目录下,文件名固定为robots.txt的(全部小写)、当搜索引擎要爬取我们网站的时候,会先读一下robots.txt里面的内容,判断哪些URL可以访问,哪些不行,然后进行爬取、收录。
Robots规则
常用的几类语法:
User-agent: 定义搜索引擎的类型
google蜘蛛:googlebot
百度蜘蛛:baiduspider
yahoo蜘蛛:slurp
alexa蜘蛛:ia_archiver
msn蜘蛛:msnbot
Disallow: 定义禁止搜索引擎收录的地址
举个例子来讲:User-agent: * Disallow: /
禁止所有搜索引擎访问网站,(*)为通配符
Allow: 定义允许搜索引擎收录的地址
User-agent: * Disallow: /a/ Allow: /a/b
如上面例子,限制搜索引擎抓取a目录,但允许搜索引擎抓取a目录下的b目录
$通配符
User-agent: * Allow: .htm$
匹配URL结尾的字符。如下面代码将允许蜘蛛访问以.htm为后缀的URL:
*通配符
User-agent: * Disallow: /*.htm
告诉蜘蛛匹配任意一段字符。如下面一段代码将禁止所有蜘蛛抓取所有htm文件:
Sitemaps位置
Sitemap: http://www.xxx.com/sitemap.xml
Robots心得
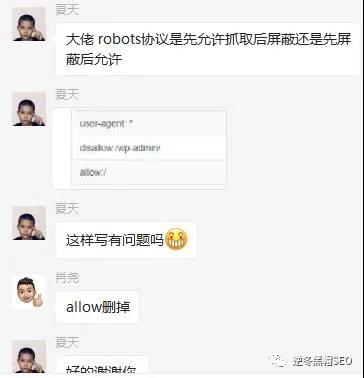
1、许多朋友都喜欢让搜索引擎不抓取自己的后台,于是将自己的后台地址写到robots.txt里面,其实个人不建议这样做,因为考虑到网络安全,许多Hack都喜欢通过robots.txt看大家的后台,方便攻击!

2、网站必须要有robots.txt,如果网站没有robots.txt,搜索引擎随意抓取的话,可能会抓取到一些低质量页面,从而导致网站收录、流量受到影响,如上图是没有robots.txt。
3、当我们做完robots.txt后,一定要去【百度站长工具平台】抓取、测试robots.txt,以及测试URL是否可以抓取。
我们专注高端建站,小程序开发、软件系统定制开发、BUG修复、物联网开发、各类API接口对接开发等。十余年开发经验,每一个项目承诺做到满意为止,多一次对比,一定让您多一份收获!










